FlaskとLangChainを使った簡単な質問応答アプリの作り方(RetrievalQA)
2024年12月1日

こんにちは!
この記事では、PythonのWebフレームワークであるFlaskと、最近注目を集めている自然言語処理ライブラリLangChainを組み合わせて、簡単な質問応答アプリを作成する方法を解説します。
初めてFlaskやLangChainに触れる方向けに、手を動かしながら学べる内容になっています。Python初心者でも理解しやすいように、具体例や例えを交えながら進めていきますので、ぜひ一緒に読み進めてみてください。
LangChainとは?
まずは、簡単にLangChainについて解説します。
LangChainは、言語モデル(LLM: Large Language Model)の活用を簡単にするためのライブラリです。具体的には以下のようなことができます。
- 大量のドキュメントを検索して質問に答える。
- 言語モデルを使って複雑なタスクを処理する。
- データベースや外部APIと連携した自然言語応答。
わかりやすく言うと、LangChainは「AIモデルを使ったアプリ開発の補助ツールボックス」です。
面倒な設定や仕組みを一括で処理してくれるため、初心者でも手軽に高度な自然言語処理を活用できます。
FlaskとLangChainを使った簡単な質問応答アプリを作ってみる
今回は、以下のように与えられた質問について、回答を出力するアプリを作成します。

上記のように、ChatGPTには無い情報をテキストデータで与えて、その内容を返すようにします。
必要なパッケージのインストール
まず、必要なパッケージのインストールを行います。
pip install flask langchain openai faiss-cpu tiktoken langchain_community langchain-openaiapp.pyの実装
続いて、app.pyの実装を行います。以下のように記述します。
from flask import Flask, request, render_template
from langchain_openai import OpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.docstore.document import Document
# Flaskアプリの初期化
app = Flask(__name__)
# OpenAIのAPIキー設定(環境変数を使用することを推奨)
import os
os.environ["OPENAI_API_KEY"] = "自身のOPEN AIのAPIを記述"
# ドキュメントの用意
documents = [
Document(page_content="『【推しの子】』は赤坂アカと横槍メンゴによる青年漫画で、2020年から2024年まで週刊ヤングジャンプで連載されました。ジャンルは転生、サスペンスで、芸能界の光と闇を描いています。"),
Document(page_content="主人公アクアは、前世の記憶を持ちながらアイドルの子供として生まれ変わり、母を殺害した犯人を探し復讐を誓います。一方で妹ルビーはアイドルとして活躍を目指します。"),
Document(page_content="作中のB小町は、主人公たちが活動するアイドルグループで、新旧2つの世代があります。旧B小町は主人公たちの母アイが所属し、新B小町はルビーたちが中心となって活動します。"),
Document(page_content="【推しの子】のアニメ版は2023年から放送が開始され、2024年には第2期が放送されました。さらに、実写化も進行中で、Amazon Prime Videoで配信され、劇場公開も予定されています。"),
Document(page_content="本作は芸能界の闇や現代社会の問題を描きつつも、復讐劇や人間ドラマが中心です。主人公アクアの復讐や、妹ルビーのアイドル活動を通じて、家族の絆や葛藤も描かれています。")
]
# ドキュメントの埋め込みとインデックスの作成
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# RetrievalQAチェーンの作成
llm = OpenAI(temperature=1)
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# ルートの定義
@app.route("/", methods=["GET", "POST"])
def index():
answer = None
if request.method == "POST":
question = request.form["question"]
response = qa_chain.invoke({"query": question})
answer = response['result']
return render_template("index.html", answer=answer)
# アプリの実行
if __name__ == "__main__":
app.run(debug=True)app.pyの解説は後ほど行います。
テンプレートの実装
テンプレート(フロントエンド)は以下のように実装します。templatesディレクトリのindex.htmlファイルに以下のように記述します。
<!doctype html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>RAG Demo</title>
</head>
<body>
<h1>質問を入力してください</h1>
<form action="/" method="post">
<input type="text" name="question" style="width: 300px;">
<input type="submit" value="送信">
</form>
{% if answer %}
<h2>回答:</h2>
<p>{{ answer }}</p>
{% endif %}
</body>
</html>これで、実装は完了です!
app.pyの解説
コードの重要な部分について順を追って説明します。
ドキュメントの準備
まず、質問応答のベースとなるドキュメントを準備します。
# ドキュメントの用意
documents = [
Document(page_content="『【推しの子】』は赤坂アカと横槍メンゴによる青年漫画で、2020年から2024年まで週刊ヤングジャンプで連載されました。ジャンルは転生、サスペンスで、芸能界の光と闇を描いています。"),
Document(page_content="主人公アクアは、前世の記憶を持ちながらアイドルの子供として生まれ変わり、母を殺害した犯人を探し復讐を誓います。一方で妹ルビーはアイドルとして活躍を目指します。"),
Document(page_content="作中のB小町は、主人公たちが活動するアイドルグループで、新旧2つの世代があります。旧B小町は主人公たちの母アイが所属し、新B小町はルビーたちが中心となって活動します。"),
Document(page_content="【推しの子】のアニメ版は2023年から放送が開始され、2024年には第2期が放送されました。さらに、実写化も進行中で、Amazon Prime Videoで配信され、劇場公開も予定されています。"),
Document(page_content="本作は芸能界の闇や現代社会の問題を描きつつも、復讐劇や人間ドラマが中心です。主人公アクアの復讐や、妹ルビーのアイドル活動を通じて、家族の絆や葛藤も描かれています。")
]
ここでは、簡単な説明文を5つ用意しました。これが検索対象となり、質問に応じて適切な回答が選ばれます。
ドキュメントの埋め込み
次に、埋め込み(embedding)を行います。
# ドキュメントの埋め込みとインデックスの作成
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)このコードは、ドキュメントを効率的に検索したり類似性に基づいて取得するために、埋め込み (embedding) を生成し、それをFAISSというライブラリを用いてベクトルストア(ベクトル検索用データ構造)に格納する処理を表しています。
FAISS (Facebook AI Similarity Search) は、大量のベクトルに対して高速な類似性検索を可能にするライブラリです。 埋め込みベクトルがFAISSに格納されると、クエリに最も類似するデータを迅速に検索できるようになります。
回答を生成する仕組みの実装
次に、言語モデル(LLM)を用いて検索した結果を基に回答を生成する仕組みを構築します。
llm = OpenAI(temperature=1)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever()
)llm = OpenAI(temperature=1)は、OpenAIのLLM(大規模言語モデル)を使うためのインスタンスを生成します。temperature=1は、出力のランダム性を制御するパラメータです。値が0に近いほど、同じ質問には常に同じ答えを返します。値が1に近いほど、出力が多様化し、クリエイティブな回答を得られやすくなります。
RetrievalQA.from_chain_typeメソッドは、質問応答(QA)タスク用のチェーンを生成します。質問に答える際、まず外部データベース(リトリーバー)を利用して情報を検索し、その結果を用いて回答を生成します。各引数の解説は以下の通りです。
- llm=llm : 質問応答に使用するLLMを指定します。先ほど生成したllm(OpenAIのモデルインスタンス)が渡されています。
- chain_type=”stuff”: 検索結果をそのままLLMに渡して回答を生成します。検索結果を直接「詰め込む」(stuffする)アプローチです。
- retriever=vectorstore.as_retriever(): リトリーバー(情報検索モジュール)を指定します。以前に作成したFAISSベクトルストアを検索用リトリーバーとして設定します。
これにより、ユーザーのクエリが埋め込みベクトルに変換され、類似性検索が実行される仕組みが確立します。
ルートの実装
最後にルートの実装です。
@app.route("/", methods=["GET", "POST"])
def index():
answer = None
if request.method == "POST":
question = request.form["question"]
response = qa_chain.invoke({"query": question})
answer = response['result']
return render_template("index.html", answer=answer)response = qa_chain.invoke({“query”: question})の部分で、先ほど作成したqa_chainオブジェクトを使って、質問に対する回答を生成します。qa_chain内部では、この辞書を元にリトリーバーで情報を検索し、LLMで回答を生成します。
Flaskの起動
最後にFlaskを起動して確認しましょう。
python app.pyブラウザにアクセスすると、以下のように表示されます。

ここで、ドキュメントに記述した内容の質問をします。
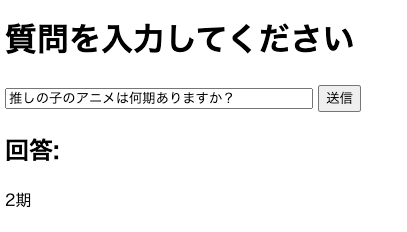
このように、与えたドキュメントの内容を返答してくれます。
まとめ
この記事では、FlaskとLangChainを使った簡単な質問応答アプリの作成方法を解説しました。
LangChainは、大規模言語モデル(LLM)とリトリーバー(検索機能)を組み合わせた強力なツールで、情報検索と自然言語応答を簡単に統合できます。また、FAISSを用いた高速なベクトル検索を活用し、効率的に関連情報を取得する仕組みを構築しました。
この記事を参考に、FlaskでのWebアプリ開発とLangChainを使ったAI活用の基本を学び、独自の応用アイデアを試してみてください。初心者でも取り組みやすい内容になっていますので、ぜひ挑戦してみてください!
Pythonの基礎から応用まで学べる
Python WebAcademy
Python WebAcademyでは、Pythonの基礎からアーキテクチャなどの応用的な内容まで幅広く学べます。また、ブラウザ上で直接Pythonコードを試すことができ、実践的なスキルを身につけることが可能です。
 Pythonの学習を始める
Pythonの学習を始める





インフラの学習はInfraAcademy

おすすめの記事








